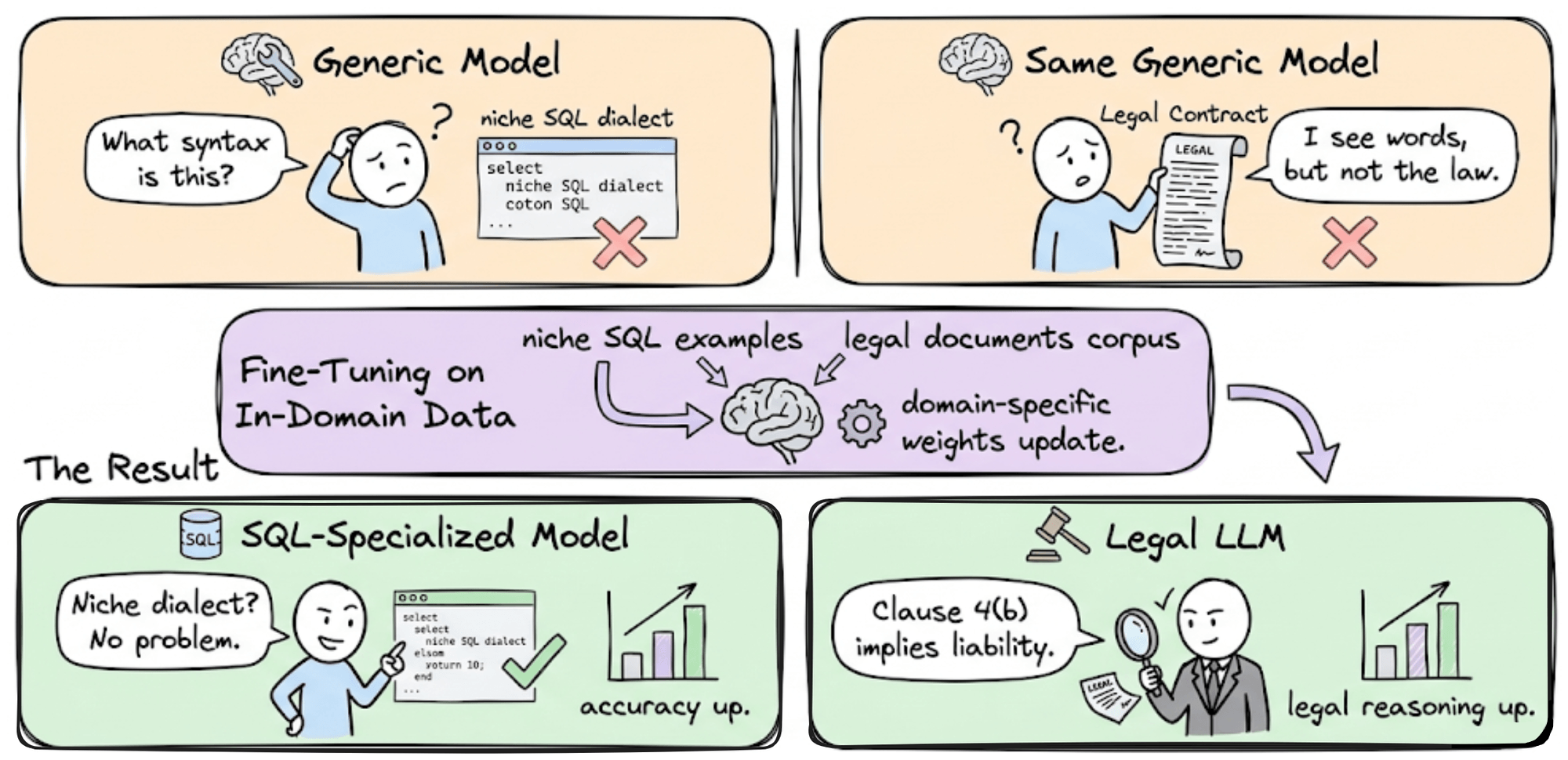
LLM Fine-tuning: Techniques for Adapting Language Models
Understanding LoRA, QLoRA, RLHF, DPO, GRPO, etc.
Soutenez Daily Dose of Data Science en consultant la ressource originale
Lire l'article originalVous aimez découvrir ces sources ?
Soutenez-moi sur Patreon

