

ImportAI 449: LLMs training other LLMs; 72B distributed training run; computer vision is harder than generative text
Will AI cause a political interregnum
Lire
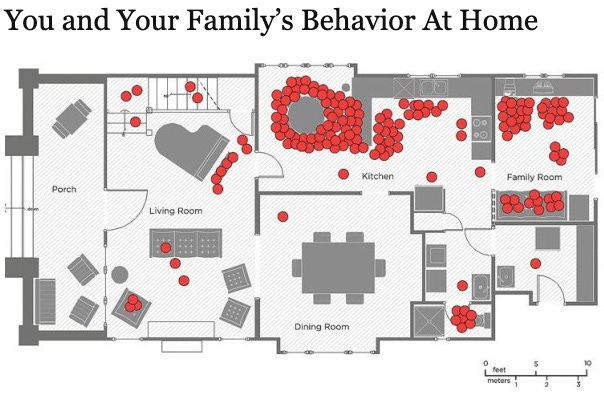

A Fraudster’s Paradise
Dark web forum posts mentioned the phrase “AI agent” far more in the second half of 2025 than in the first half. Could this mean that fraudsters are charmed by the AI hype? Or is AI truly a game changer for cybercrime? AI-related discussions—evident both in what “the bad guys” are saying and in what […]
Lire

BREAKING: Sam Altman concedes that we need major breakthroughs beyond mere scaling to get to AGI
It’s past time to look for new architectures
Lire
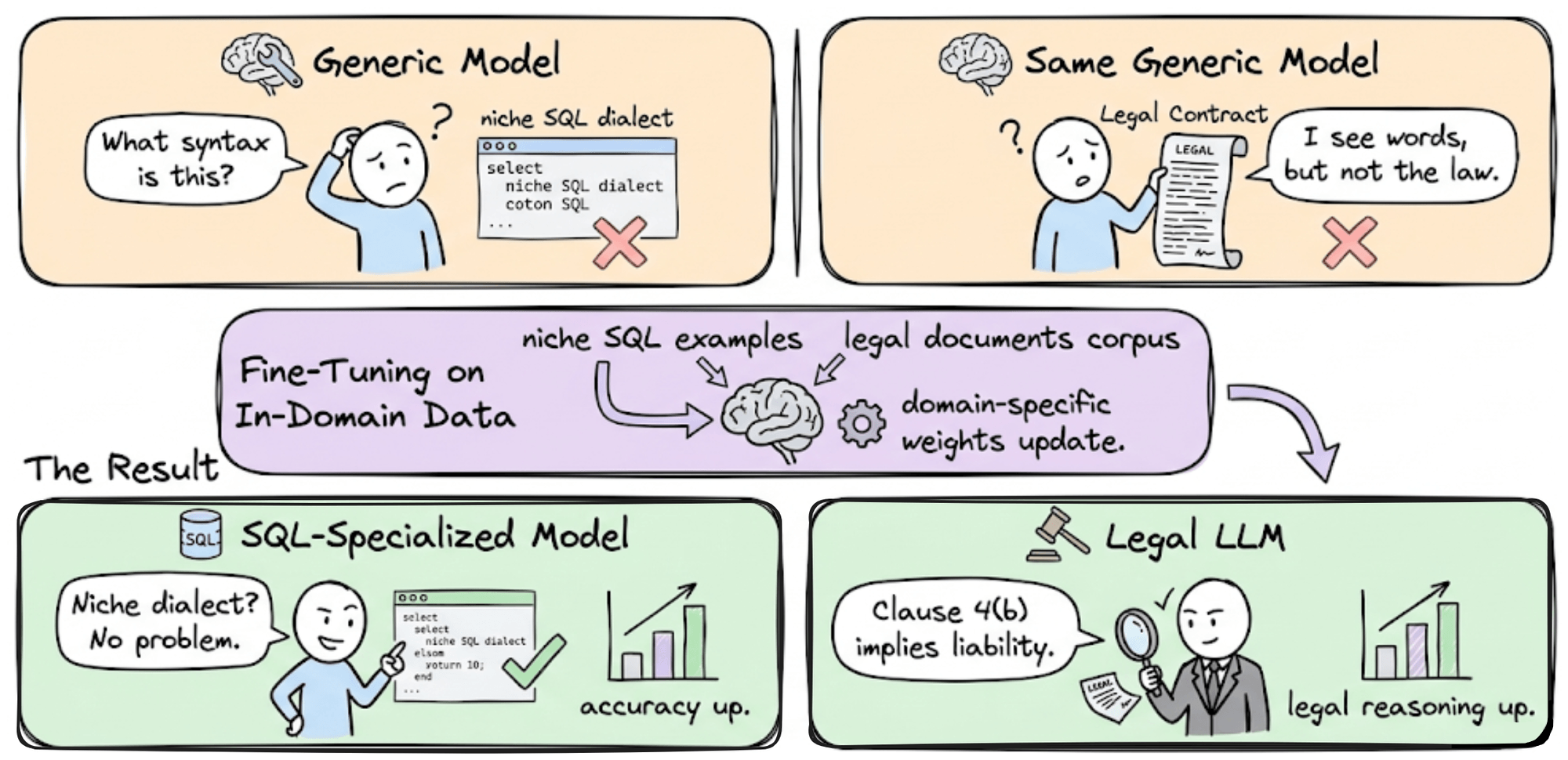
LLM Fine-tuning: Techniques for Adapting Language Models
Understanding LoRA, QLoRA, RLHF, DPO, GRPO, etc.
Lire

BREAKING: Expensive new evidence that scaling is not all you need
Two more colossally expensive experiments have failed
Lire
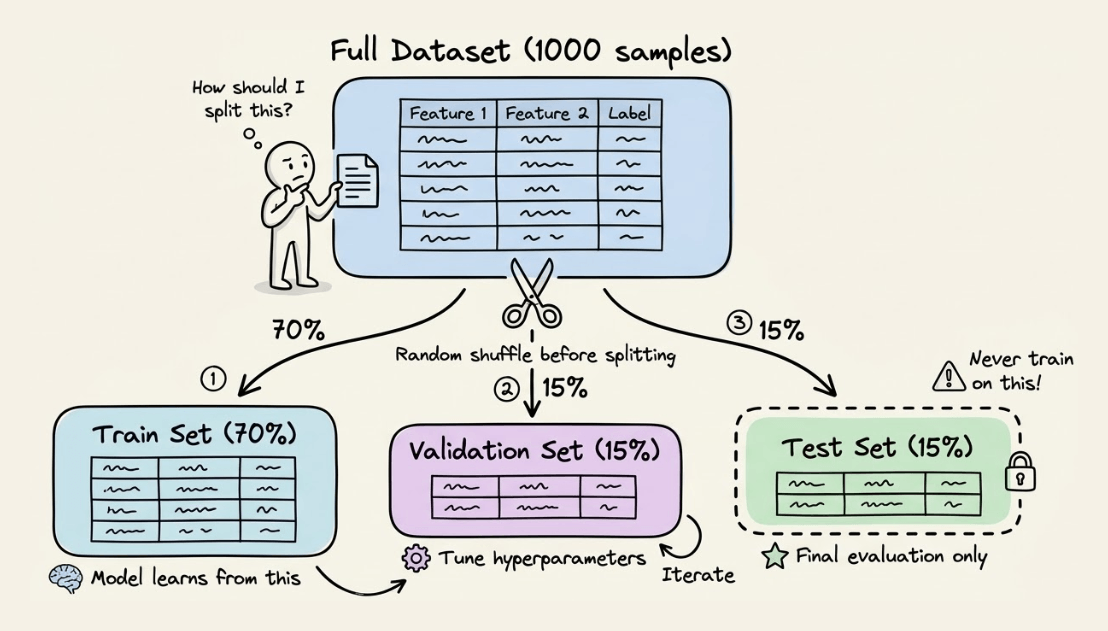
How to Actually Use Train, Validation, and Test Sets in ML
...explained visually!
Lire
Software Craftsmanship in the Age of AI
Software Craftsmanship in the Age of AI
On March 26, Addy Osmani and I are hosting the third O’Reilly AI Codecon, and this time we’re taking on the question of what software craftsmanship looks like when AI agents are writing much of the code. The subtitle of this event, “Software Craftsmanship in the Age of AI,” was meant to be provocative. Craftsmanship […]
Lire

Capability Architecture for AI-Native Engineering
A few years into the AI shift, the gap between engineers is not talent. It’s coordination: shared norms and a shared language for how AI fits into everyday engineering work. Some teams are already getting real value. They’ve moved beyond one-off experiments and started building repeatable ways of working with AI. Others haven’t, even when […]
Lire

Identifying Interactions at Scale for LLMs
--> Understanding the behavior of complex machine learning systems, particularly Large Language Models (LLMs), is a critical challenge in modern artificial intelligence. Interpretability research aims to make the decision-making process more transparent to model builders and impacted humans, a step toward safer and more trustworthy AI. To gain a comprehensive understanding, we can analyze these systems through different lenses: feature attribution, which isolates the specific input features…
Lire
Set Up a Secure OpenClaw Deployment!
...explained in step-by-step guide!
Lire
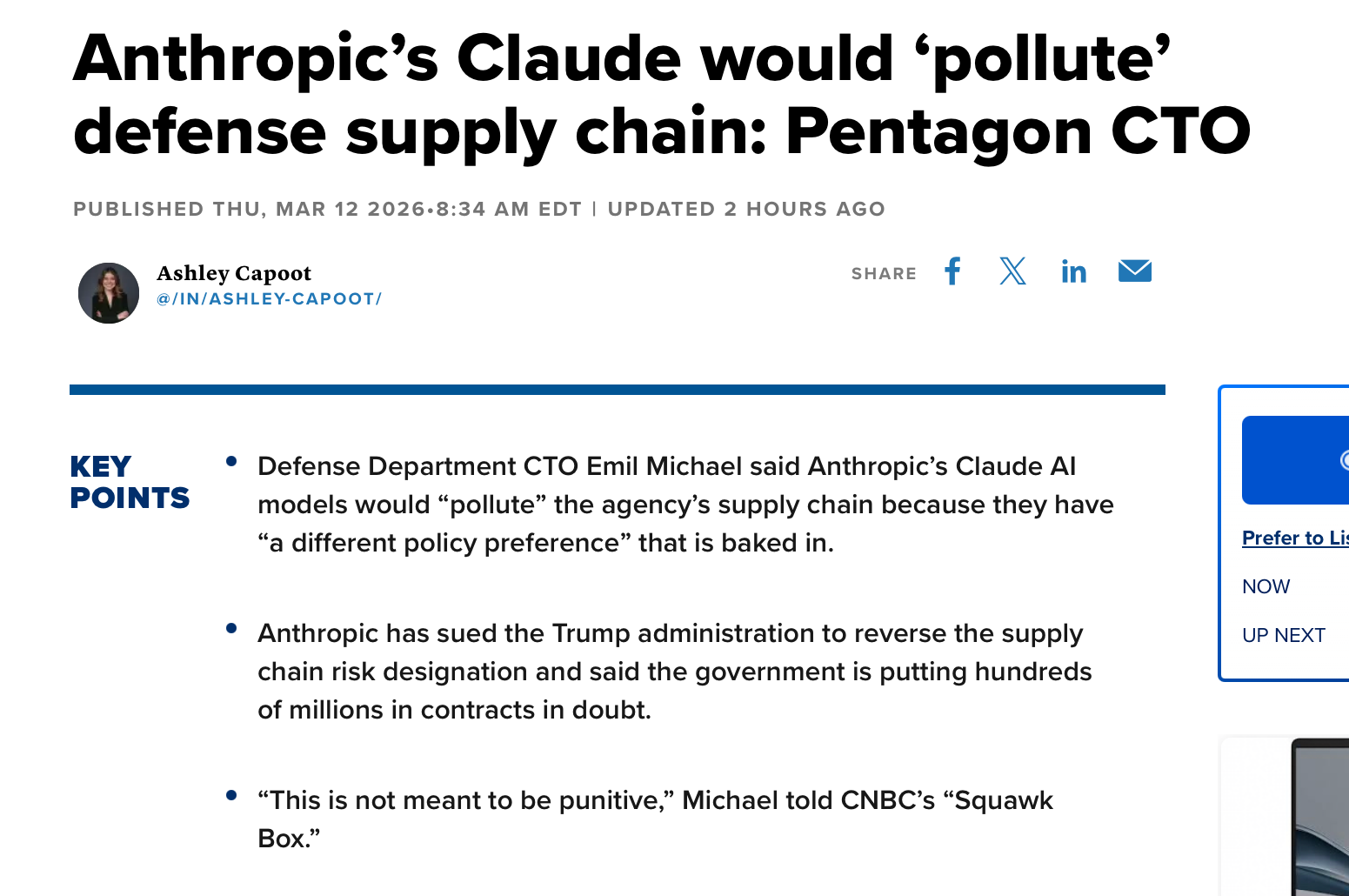
Is the US military actually afraid of Claude? A new theory of why Anthropic was labeled a supply chain risk.
Unpacking a perplexing argument from the Pentagon
Lire

AI #159: See You In Court
The conflict between Anthropic and the Department of War has now moved to the courts, where Anthropic has challenged the official supply chain risk designation as well as the order to remove it from systems across the government, claiming retaliation for protected speech.
Lire